Apply NLP to Genre Analysis of Abstract Sections in Research Articles Across Hard Sciences
Introduction
The abstract section of research articles serves as a concise and informative summary, playing a crucial role in aiding scholars, researchers, and practitioners in understanding the scope and significance of a study. This quantitative study delves into the genre analysis of abstract sections in six diverse scientific disciplines: Computer Science, Physics, Mathematics, Statistics, Quantitative Biology, and Quantitative Finance. Leveraging a dataset of research article abstracts, we aim to use NLP techniques to identify common words and linguistic patterns unique to each field or shared by all the fields, providing insights into how research findings are communicated within and across disciplines.
Methodology and Results
To conduct the quantitative analysis, we utilized the mentioned dataset of research article abstracts (20972 abstracts) available on Kaggle.com, representing various subfields within the 6 selected disciplines.
Using natural language processing (NLP) techniques and computational tools, we parsed the abstracts to extract word frequency data. This approach allowed us to identify the most common words in the abstract sections of research articles within each discipline.
This study contributes to the understanding of interdisciplinary communication patterns and offers implications for language educators, researchers, and practitioners. The quantified knowledge of common words and their relative prominence within each field can assist in designing targeted English for Academic Purposes (EAP) courses and enhancing academic literacy for students and researchers alike.
Here is the results of our analysis:
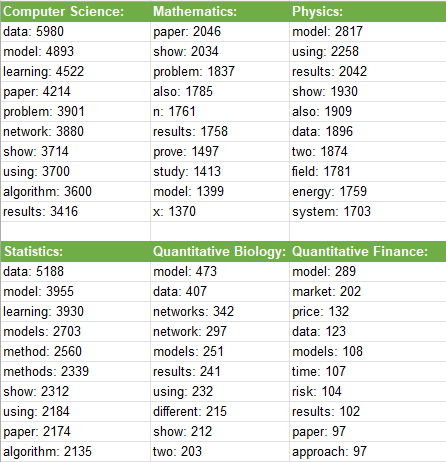
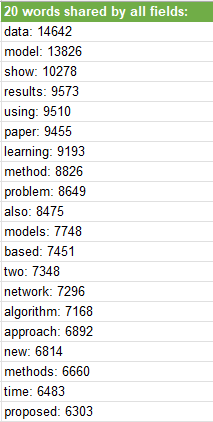
Application and Code
To extract the most common words in the abstracts of each field from your dataset, you can follow these steps:
- Prepare the data: Create separate datasets for each field by filtering the rows where the corresponding field column has a value of 1.
- Text Preprocessing: Preprocess the abstracts to clean the text data, perform tokenization, and remove stop words.
- Count the Term Frequencies: Use the
Counterfrom Python’scollectionsmodule to count the frequency of each term (word) in the abstracts of each field. - Sort the Frequencies: Sort the terms based on their frequencies in descending order.
- Select the Most Common Words: Choose the top N most common words to represent the most frequent words in each field.
# import the necessary libraries
import pandas as pd
from collections import Counter
from nltk.corpus import stopwords
import nltk
nltk.download('stopwords')# we read the csv
df = pd.read_csv('../input/urban-sound/train_tm/train.csv')# check the first 5 rows
df.head()
# Prepare the data
fields = ['Computer Science', 'Mathematics', 'Physics', 'Statistics', 'Quantitative Biology', 'Quantitative Finance']
field_data = {}
for field in fields:
field_data[field] = df[df[field] == 1]# Text Preprocessing
stop_words = set(stopwords.words('english'))
def preprocess_text(text):
words = nltk.word_tokenize(text.lower())
words = [word for word in words if word.isalpha() and word not in stop_words]
return wordsIt is time to find common words according to the field of study:
# Count the Term Frequencies
most_common_words_by_field = {}
for field, data in field_data.items():
abstracts = data['ABSTRACT'].tolist()
all_words = []
for abstract in abstracts:
all_words.extend(preprocess_text(abstract))
word_counts = Counter(all_words)
most_common_words = dict(word_counts.most_common(10)) # Get top 10 most common words
most_common_words_by_field[field] = most_common_words
# Sort the Frequencies (already done using Counter)
# Step 5: Select the Most Common Words (already done selecting the top 10)
# Print the most common words for each field
for field, common_words in most_common_words_by_field.items():
print(f"Most common words in {field}:")
for word, count in common_words.items():
print(f"{word}: {count}")
print()It is time to find common words shared by all the fields:
# Count the Term Frequencies
word_counts_by_field = {}
for field, data in field_data.items():
abstracts = data['ABSTRACT'].tolist()
all_words = []
for abstract in abstracts:
all_words.extend(preprocess_text(abstract))
word_counts_by_field[field] = Counter(all_words)
# Identify words shared by all fields
common_words = set(word_counts_by_field[fields[0]].keys())
for field in fields[1:]:
common_words = common_words.intersection(set(word_counts_by_field[field].keys()))
# Select the Most Common Words
most_common_words = dict(Counter({word: sum(word_counts_by_field[field][word] for field in fields) for word in common_words}).most_common(20))
# Print the most common 20 words shared by all fields
print("Most common 20 words shared by all fields:")
for word, count in most_common_words.items():
print(f"{word}: {count}")