text Analysis with Python: Spacy and TextBlob
What is text analysis?
Text analysis is the process of using computer systems to read and understand human-written text for business insights.
https://aws.amazon.com/what-is/text-analysis/
The above definition does not cover the text analysis done manually by researchers in social sciences. So, generally, text analysis is the process of examining and understanding texts using various techniques and methods in order to extract meaningful insights and patterns. Text analysis techniques using computer systems can range from basic tasks such as text cleaning, tokenization, and counting word frequencies, to more complex tasks such as text classification, sentiment analysis, topic modeling, and natural language processing (NLP).
In today’s data-driven world, text analysis has become an essential tool for understanding and extracting insights from vast amounts of unstructured data. With the rise of social media, online reviews, and customer feedback, text analysis has become increasingly important in fields such as marketing, customer service, and research. Python, being a popular language for data analysis, provides a wide range of libraries and tools for text analysis, making it an excellent choice for anyone looking to perform text analysis tasks.
In this blog post, I will explore various approaches to text analysis and popular Python libraries that can be used for text analysis. In a previous post, I explained how you can work with the Stanza library to analyze texts. In hits post, I will focus on Spacy, a popular library for natural language processing, and explore its text preprocessing capabilities, including tokenization, lemmatization, and stop word removal. Additionally, I will dive into sentiment analysis with TextBlob, a Python library built on top of NLTK. By the end of this blog post, you will have a good understanding of text analysis with Python and be able to apply these techniques to your own text analysis tasks.
Text Preprocessing
Text preprocessing is an important step in any text analysis task, as it helps to clean and transform the raw text into a more structured format that can be easily analyzed. Spacy, a popular natural language processing library in Python, provides various tools for text preprocessing, including tokenization, lemmatization, and stop word removal.
- Installing Spacy: Before we can start using Spacy, we need to install it. You can install Spacy using pip, a package manager for Python. Simply run the following command in your terminal or command prompt:
pip install spacy- Importing and loading the Spacy model: Once Spacy is installed, we need to load a language model that can be used for text preprocessing. Spacy provides various pre-trained models for different languages, including English, Spanish, German, and more. You can load the English model by running the following code:
import spacy
nlp = spacy.load("en_core_web_sm")
This will load the English language model into the nlp object.
- Tokenization of text using Spacy: Tokenization is the process of splitting the text into individual words or tokens. Spacy provides a tokenizer that can split the text into tokens based on various rules. You can tokenize a text by calling the
nlpobject on the text and iterating over thedocobject to get the individual tokens:
text = "This is a sample sentence."
doc = nlp(text)
for token in doc:
print(token.text)
This will output:
This
is
a
sample
sentence
.- Lemmatization of tokens using Spacy: Lemmatization is the process of reducing words to their base or dictionary form. Spacy provides a lemmatizer that can be used to lemmatize tokens. You can lemmatize a token by accessing its
lemma_attribute:
for token in doc:
print(token.text, token.lemma_)This will output:
This this
is be
a a
sample sample
sentence sentence
. .Note that the lemmatized form of “is” is “be”, which is the base form of the verb.
- Removing stop words using Spacy: Stop words are common words that do not carry much meaning and can be removed from the text without affecting the overall meaning of the text. Spacy provides a list of stop words that can be used to remove stop words from the text. You can remove stop words from a text by iterating over the tokens and checking if the token is a stop word and use isalpha() method to remove punctuations:
for token in doc:
if not token.is_stop and token.text.isalpha():
print(token.text)This will output:
sample
sentenceOverall, Spacy provides powerful tools for text preprocessing, making it easier to clean and transform raw text into a more structured format that can be easily analyzed.
Sentiment analysis with TextBlob
Sentiment analysis is the process of analyzing and classifying the sentiment of a piece of text, whether it’s positive, negative, or neutral. With the increasing amount of user-generated content online, sentiment analysis has become a crucial tool for businesses and organizations to monitor and understand their customers’ opinions and feedback.
TextBlob is a Python library that provides a simple and intuitive interface for performing sentiment analysis on text. TextBlob’s sentiment analysis module is based on a pre-trained machine learning model that can classify text as positive, negative, or neutral. This library uses a combination of pattern recognition and rule-based techniques to determine the sentiment polarity of text. One of the advantages of using TextBlob for sentiment analysis is that it is very easy to use and does not require any specialized knowledge or training. Additionally, TextBlob can be used in combination with other natural language processing libraries, such as Spacy, to build more complex text analysis pipelines.
Download and install TextBlob:
!pip install -U textblob
!python -m textblob.download_corporaYou can use Spacy to preprocess the text and extract the relevant features, and then use TextBlob to classify the sentiment. Here’s an example code snippet that demonstrates how to use TextBlob for sentiment analysis on a preprocessed text using Spacy:
import spacy
from textblob import TextBlob
from textblob.sentiments import NaiveBayesAnalyzer
nlp = spacy.load("en_core_web_sm")
def preprocess_text(text):
# Tokenize the text using Spacy
doc = nlp(text)
# Remove stop words
filtered_tokens = [token.lemma_ for token in doc if not token.is_stop and token.text.isalpha()]
# Join the tokens back into a string
preprocessed_text = " ".join(filtered_tokens)
return preprocessed_text
text = "This movie was terrible, I hated it."
# Cleaning up the text
preprocessed_text = preprocess_text(text)
# Create an instance of TextBlob with the cleaned text
blob = TextBlob(preprocessed_text)
# Getting the polarity of text which is between -1 (negative) and 1 (positive)
polarity = blob.sentiment.polarity
if polarity > 0.3:
print("Positive")
elif polarity < -0.3:
print("Negative")
else:
print("Neutral")
Text Analysis in practice
I have a csv file with ten movie reviews. I know it is not a lot, it is just for practice. I am going to provide the whole code for preprocessing, that is preparing the text for analysis, then analyze the sentiment of each review and create a label column to display it. Here is the file. There is only one column for now:

Let’s code!
import spacy
import pandas as pd
from textblob import TextBlob
# Load Spacy model for text preprocessing
nlp = spacy.load("en_core_web_sm")
# Load CSV file into a pandas DataFrame
df = pd.read_csv("review.csv")
# Define a function to preprocess text using Spacy
def preprocess_text(text):
# Tokenize the text using Spacy
doc = nlp(text)
# Remove stop words
filtered_tokens = [token.lemma_ for token in doc if not token.is_stop and token.text.isalpha()]
# Join the tokens back into a string
preprocessed_text = " ".join(filtered_tokens)
return preprocessed_text
# Define a function to classify sentiment using TextBlob
def classify_sentiment(text):
# Create a TextBlob object
blob = TextBlob(text)
# Get the polarity score
polarity = blob.sentiment.polarity
# Classify the sentiment label based on the polarity score
if polarity > 0.3:
sentiment_label = "positive"
elif polarity < -0.3:
sentiment_label = "negative"
else:
sentiment_label = "neutral"
return sentiment_label
# Apply text preprocessing and sentiment analysis to the 'text' column of the DataFrame
df['preprocessed_text'] = df['review'].apply(preprocess_text)
df['sentiment_label'] = df['preprocessed_text'].apply(classify_sentiment)
# Save the updated DataFrame to a new CSV file
df.to_csv("my_processed_csv_file.csv", index=False)
This is the results:
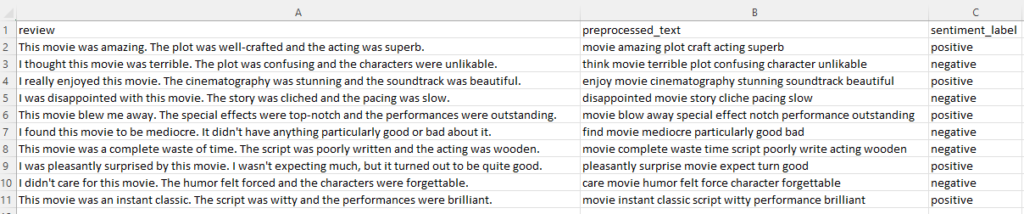
Now we have three columns, one is the review, next is the processed text, and the last is the sentiment label for each review!