NLP with Stanza: Guide to an NLP package for many languages
Introduction
Text analysis is an important area of Natural Language Processing (NLP) that deals with the automatic extraction of meaningful information from text data. There are a few well-known Python libraries such as SpaCy and NLTK for processing the natural language. One of the least-mentioned tools for text analysis is the Stanza NLP package, which is a Python NLP package developed by the Stanford University NLP group. Stanza is a powerful, accurate, and efficient package that provides a wide range of NLP tools and features. It also has models that support analysis of more than 70 languages!
In this article, we will provide a comprehensive guide on text analysis using Stanza, including installation, usage, and examples.
Stanza Neural Pipeline
The following image shows Stanza’s neural network NLP pipeline.
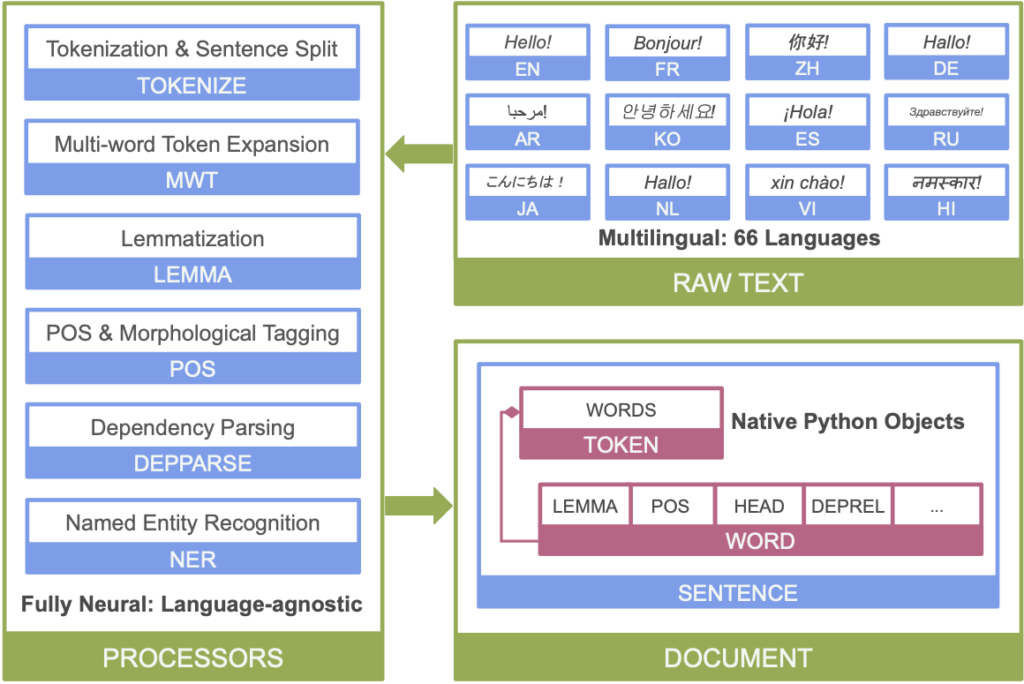
Before going through the diagram and explain it, let’s install stanza:
pip install stanzaAfter installing Stanza, we need to download the language models that we want to use. Stanza provides pre-trained language models for many languages. The following minimal example will download and load default processors into a pipeline for English:
import stanza
stanza.download('en') # Download the English language model
nlp = stanza.Pipeline('en') # initialize English neural pipeline
Now that we have installed Stanza and downloaded a language model, let’s discuss how to use the package for text analysis. Stanza provides a wide range of NLP tools, including tokenization, part-of-speech tagging, named entity recognition, dependency parsing, and sentiment analysis. You can specify a particular processor to use. Here’s an overview of these tools and how to use them:
Sentence segmentation
A text is received as input and then processed by the various processors to segment the text into sentences. In this example, I am using the default pipeline with all the processors loaded.
import stanza
nlp = stanza.Pipeline()
doc = nlp("This is the first sentence. This is the second sentence.")
for sentence in doc.sentences:
print(sentence.text)
# Output will be :
# This is the first sentence.
# This is the second sentence.Tokenization
Tokenization is the process of splitting a text document into individual words or tokens. In case of multi-word tokens in languages such as Spanish (for example ¡Dámelo! which looks like one word but consists of dá – me – lo), Stanza expands them into different tokens.
import stanza
nlp = stanza.Pipeline(lang='en', processors='tokenize')
doc = nlp("This is a sample sentence.")
for sentence in doc.sentences:
for token in sentence.tokens:
print(token.text)
# Output will be :
# This
# is
# a
# sample
# sentence
# .Lemmatization
Process of lemmatization involves taking the tokens and convert them to their original dictionary form (without inflection). For example, went becomes go and am becomes be. This is specially useful if you want to analyze the lexical choices in a text. This way, you would not worry about all the different forms a word can take: do, doing, did, does, done!
import stanza
nlp = stanza.Pipeline()
doc = nlp("This is an apple.")
for sentence in doc.sentences:
for word in sentence.words:
print(word.lemma)
# Output will be :
# This
# be
# a
# apple
Part-of-speech tagging
Part-of-speech (POS) tagging is the process of assigning a grammatical category such nouns, adjectives, verbs,… to each word in a text document. Stanza provides a POS tagging tool that can be used as follows:
import stanza
nlp = stanza.Pipeline()
doc = nlp("This is a sample sentence.")
for sentence in doc.sentences:
for token in sentence.tokens:
print(token.text, token.pos)
# This DET
# is AUX
# a DET
# sample NOUN
# sentence NOUN
# . PUNCTNamed entity recognition
Named entity recognition (NER) is the process of identifying named entities such as people, organizations, and locations in a text document. Stanza provides a NER tool that can be used as follows:
import stanza
nlp = stanza.Pipeline()
doc = nlp("Barack Obama was born in Hawaii.")
# You can either use
print(doc.ents)
# or
for sentence in doc.sentences:
for entity in sentence.ents:
print(entity.text, entity.type)Dependency parsing
Dependency parsing is the process of analyzing the syntactic structure of a sentence and identifying the relationships between words. Stanza provides a dependency parsing tool that can be used as follows:
import stanza
# load the language model for your chosen language
nlp = stanza.Pipeline(lang='en', processors='tokenize,mwt,pos,lemma,depparse')
# parse a sentence and print the dependency parse tree
doc = nlp("this is an apple.")
print(doc.sentences[0].dependencies)The output is a Python list with each token’s relationship to others and their lemma, POS, and the head. Refer to this article to know more about Dependency structure and Constituency structure which I am explaining next.
Constituency Parser
If you are looking for constituency / phrase structure, then this is how Stanza does it:
import stanza
nlp = stanza.Pipeline(lang='en', processors='tokenize,pos,constituency')
doc = nlp('This is a test')
for sentence in doc.sentences:
print(sentence.constituency)
# Output will be
# (ROOT (S (NP (DT This)) (VP (VBZ is) (NP (DT a) (NN test)))))
# you can go further down in the tree
tree = doc.sentences[0].constituency
print(tree.label)
print(tree.children)
print(tree.children[0].children)Sentiment for English, Chinese, German
you can analyze the sentiment of a text using Stanza by the following code. Note that you get a score from 0 to 2. Number 0 means Negative,1 means Neutral, and 2 means Positive.
import stanza
nlp = stanza.Pipeline()
doc = nlp('I love Chomsky's universal grammar.')
for i in doc.sentences:
print(i.sentiment)
# Output will be
# 2Conclusion
In this article I tried to show how you can use Stanza NLP package which is a Python interface for Stanford CoreNLP, to analyze natural language, tokenize texts, lemmatize them, tag the parts of speech, recognize the named entities, parse dependency and phrase structure, and analyze the sentiment.
Obviously there much more to Stanza NLP package than that. You can train models and specially you can use their Biomedical models to analyze Biomedical texts. If you liked the article, consider subscribing to Pythonology Youtube video channel!