Are you looking to enhance your natural language processing projects with the latest AI technologies? I have already several posts on NLP that you can read, for example HERE. In this tutorial, we’ll walk you through creating a Retrieval-Augmented Generation (RAG) application that doubles as a web scraper. We’ll be using tools like LangChain, Ollama, and Chroma to build a powerful system that can extract, process, and generate information from web content.
What You’ll Learn
- How to scrape web content using LangChain’s WebBaseLoader
- Techniques for text splitting and embedding generation
- Setting up a vector store with Chroma
- Implementing a retrieval system for relevant information
- Generating responses using a language model
But before we dive into the code, let’s break down some key concepts to ensure everyone’s on the same page.
Key Concepts Explained
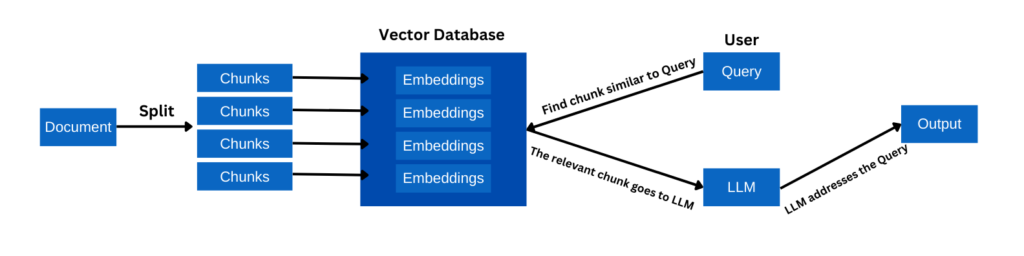
What is RAG (Retrieval-Augmented Generation)?
RAG is a technique that combines the power of large language models with the ability to retrieve relevant information from a knowledge base. This allows the model to generate more accurate and contextually appropriate responses by referencing external data.
What is LangChain?
LangChain is a framework for developing applications powered by language models. It provides a set of tools and components that make it easier to build complex AI applications, including features for document loading, text splitting, and integrating with various AI models and databases.
What is Ollama?
Ollama is an open-source project that allows you to run large language models locally on your machine. It provides a simple interface for running and interacting with various AI models, making it easier to integrate advanced AI capabilities into your applications.
What is Chroma?
Chroma is an open-source vector database that allows you to store and query high-dimensional vectors efficiently. In the context of natural language processing, it’s used to store and retrieve text embeddings, which are numerical representations of text that capture semantic meaning.
Now, let’s dive into the code and break it down step by step!
Step 1: Web Scraping with LangChain
Let’s install what we need:
pip install requests
pip install beautifulsoup4
pip install langchain-community
First, we’ll use LangChain’s WebBaseLoader to scrape content from a specific URL:
import bs4
from langchain_community.document_loaders import WebBaseLoader
bs4_strainer = bs4.SoupStrainer(class_=("content-area"))
loader = WebBaseLoader(
web_paths=("https://pythonology.eu/using-pandas_ta-to-generate-technical-indicators-and-signals/",),
bs_kwargs={"parse_only": bs4_strainer},
)
docs = loader.load()In this step, we’re using BeautifulSoup’s SoupStrainer to focus on the “content-area” class, ensuring we only extract relevant information. The WebBaseLoader then fetches and processes the specified URL.
Step 2: Text Splitting for Manageable Chunks
First download this:
pip install langchain-text-splittersWhat does RecursiveCharacterTextSplitter do?
The RecursiveCharacterTextSplitter is a tool that breaks down large pieces of text into smaller, more manageable chunks. It does this “recursively,” meaning it starts with the whole text and progressively splits it into smaller pieces based on certain criteria (like character count).
Why is this important? Large language models often have a limit on the amount of text they can process at once. By splitting the text into smaller chunks, we can process large documents more efficiently and maintain context between related pieces of information.
Now, we split the extracted text into smaller, more manageable chunks:
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1200, chunk_overlap=100, add_start_index=True
)
all_splits = text_splitter.split_documents(docs)Step 3: Generating Embeddings with Ollama
Important: Download Ollama on your machine from their official website.
Then in your terminal use these commands to download a language model and an embedding model:
ollama run llama3.2:1b
ollama pull all-minilmNext, we’ll create embeddings for our text chunks using Ollama and store it in Chroma vector store:
Install this:
pip install langchain-chromafrom langchain_community.embeddings import OllamaEmbeddings
from langchain_chroma import Chroma
local_embeddings = OllamaEmbeddings(model="all-minilm")
vectorstore = Chroma.from_documents(documents=all_splits, embedding=local_embeddings)What are embeddings and why do we need them?
Embeddings are numerical representations of text that capture semantic meaning. They convert words or phrases into vectors (lists of numbers) in a high-dimensional space. In this space, semantically similar pieces of text are closer together.
We need embeddings because they allow us to:
- Represent text in a format that machines can understand and process efficiently.
- Perform semantic searches, finding pieces of text that are similar in meaning, not just identical in wording.
- Use advanced machine learning techniques on text data.
What is a vector store?
A vector store is a specialized database designed to store and efficiently query high-dimensional vectors (like our text embeddings). In our case, Chroma is serving as our vector store. It allows us to:
- Store the embeddings of our text chunks.
- Quickly find the most similar embeddings to a given query.
- Retrieve the original text associated with these similar embeddings.
This is crucial for our RAG system, as it allows us to quickly find relevant information based on the semantic meaning of a query.
Step 4: Implementing the Retrieval System
With our vector store set up, we can now implement a retrieval system:
question = "what are the oversold and overbought periods?"
retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 3})
retrieved_docs = retriever.invoke(question)This system allows us to find the most relevant documents based on a given question, using similarity search to retrieve the top 3 matches.
Now we can convert the first three matches into a a text and then feed it to the LLM as a context, based on which it can answer our question:
context = ' '.join([doc.page_content for doc in retrieved_docs])Step 5: Generating Responses with a Language Model
Finally, we use Ollama’s language model to generate a response based on the retrieved context:
Download this:
pip install -U langchain-ollamafrom langchain_ollama.llms import OllamaLLM
llm = OllamaLLM(model="llama3.2:1b")
response = llm.invoke(f"""Answer the question according to the context given very briefly:
Question: {question}.
Context: {context}
""")This step combines the power of retrieval and generation, providing concise and relevant answers based on the scraped and processed web content.
Conclusion
By following this tutorial, you’ve learned how to create a sophisticated RAG application that can scrape web content, process it efficiently, and generate informative responses. This powerful combination of LangChain, Ollama, and Chroma opens up endless possibilities for natural language processing projects.
We’ve covered key concepts like:
- Text splitting with RecursiveCharacterTextSplitter
- Embedding generation and the importance of vector representations
- Vector stores and their role in efficient information retrieval
- The use of local language models with Ollama
Whether you’re building a chatbot, a question-answering system, or a content summarization tool, the techniques covered here provide a solid foundation for your AI-powered applications.